1. Installing Python and some tools#
1.1. Main Python distributions for data sciences#
When starting with Python for data science, it’s important to know the main distributions you can use. These distributions include Python itself, plus tools to manage packages and environments. Here’s an overview that works across macOS, Linux, and Windows.
System Python#
Many operating systems come with Python pre-installed:
macOS and most Linux distributions include Python.
Windows does not come with Python pre-installed (you need to download it from Python.org).
Usually an older version (e.g., Python 3.8 or 3.9).
Good for simple scripts, but installing additional packages may conflict with system tools.
Official Python from Python.org#
The official Python distribution is available at python.org.
Works on macOS, Linux, and Windows.
You can manually install any additional data science packages (e.g.,
numpy,pandas,matplotlib) usingpip.Lightweight and cross-platform, but you need to manage dependencies yourself.
Anaconda#
A full Python distribution for scientific computing and data science.
Includes:
Python itself
Hundreds of pre-installed libraries (numpy, pandas, matplotlib, scipy, etc.)
Jupyter Notebook / JupyterLab
Works on macOS, Linux, and Windows.
Large download (~3 GB), but everything is ready-to-use.
Good choice if you want a complete environment for data science without installing each library manually.
Miniconda#
A minimal version of Anaconda, including only Python + the
condapackage manager.You install only the packages you need.
Works on macOS, Linux, and Windows.
Lightweight, flexible, and suitable for reproducible environments.
Often preferred for creating isolated Python environments per project.
Platform-Specific Package Managers (optional)#
macOS: Homebrew can install Python (
brew install python@3.13).Linux: System package managers like
apt(Debian/Ubuntu) ordnf/yum(Fedora/CentOS) can install Python.Windows: Chocolatey can install Python (
choco install python) if you prefer command-line installation.
⚠️ These install system-wide Python, not isolated environments, so careful with package conflicts.
💡 Mac users: Homebrew is a great tool to install system software on macOS, but it’s generally not recommended to use brew-installed Python for data science projects. Why? Because brew installs Python system-wide, which can conflict with project-specific environments like conda or venv. For isolated, reproducible Python environments, prefer Miniconda or Anaconda instead.
Summary Table#
Distribution |
Platforms |
Main Feature |
Notes |
|---|---|---|---|
System Python |
macOS/Linux |
Pre-installed |
Might be old; not isolated |
Python.org |
macOS/Linux/Windows |
Official Python |
Lightweight; manual package management |
Anaconda |
macOS/Linux/Windows |
Full scientific stack |
Large; ready-to-use |
Miniconda |
macOS/Linux/Windows |
Minimal + conda |
Lightweight; flexible |
Homebrew / apt / dnf / Chocolatey |
macOS/Linux/Windows |
System package manager |
Installs Python and other software system-wide; not isolated |
This gives you a clear overview of the main Python distributions you can use for data science, regardless of your operating system. Installation instructions and environment setup can be covered later.
Important
⇨ We will therefore focus on the Anaconda solution
1.2. Installing Anaconda and Miniconda#
Installing Anaconda#
macOS: Go to the Anaconda Downloads page, download the macOS installer (Graphical or command-line), open the .pkg file, and follow the instructions. Open a terminal and verify the installation:
conda --version
Linux: Download the Linux installer from Anaconda Downloads. Open a terminal and run:
bash ~/Downloads/Anaconda3-<version>-Linux-x86_64.sh
Follow the prompts to complete the installation. Verify with:
conda --version
Windows: Download the Windows installer from Anaconda Downloads. Run the .exe file and follow the instructions. Open Anaconda Prompt or PowerShell and verify:
conda --version
Installing Miniconda#
macOS: Go to the Miniconda Downloads page, download the macOS installer, open the .pkg file, and follow the instructions. Open a terminal and verify:
conda --version
Linux: Download the Linux installer from Miniconda Downloads. Open a terminal and run:
bash ~/Downloads/Miniconda3-latest-Linux-x86_64.sh
Follow the prompts to complete the installation. Verify with:
conda --version
Windows: Download the Windows installer from Miniconda Downloads. Run the .exe file and follow the instructions. Open Anaconda Prompt or PowerShell and verify:
conda --version
Tips and Notes#
Optionally add conda to your PATH during installation to use it from any terminal.
Update conda after installation:
conda update conda
Miniconda is recommended for a lightweight setup.
Usage of conda environments and package installation will be covered in later sections.
Summary Table#
1.3. Conda#
Conda is a package manager for Python and other languages. It helps you install packages and manage dependencies easily.
Basics#
# check that it is correctly installed:
conda --version
# keep Conda up-to-date with:
conda update conda
# install a package (Replace `numpy` with the desired package name):
conda install numpy
# install a specific version:
conda install numpy=1.25
# install multiple packages at once:
conda install numpy pandas matplotlib
# updating packages:
conda update numpy
# removing packages:
conda remove numpy
# searching for packages(replace `package_name` with the
# name of the package you want to find):
conda search package_name
Conda tips#
Update Conda regularly to get bug fixes and security updates.
If a package is not found, check alternative channels:
conda install -c conda-forge package_name
Summary of common Conda commands#
Task |
Command |
|---|---|
Check Conda version |
|
Update Conda |
|
Install package |
|
Install specific version |
|
Install multiple packages |
|
Update package |
|
Remove package |
|
Search for package |
|
Install from channel |
|
1.4. Conda virtual environment#
Using Virtual Environments#
Why Use a Virtual Environment in Python?#
The problem without a virtual environment:
By default, when you install a library with
pip install, it goes into the system-wide Python.Risks:
⚠️ Version conflicts between projects (e.g., one project needs
numpy==1.20, anothernumpy==1.26).⚠️ Risk of breaking system tools that rely on Python (macOS and Homebrew depend on it).
⚠️ Environment quickly polluted with dozens of unnecessary packages.
Solution: Virtual Environments#
A virtual environment = an isolated copy of Python with its own libraries.
Advantages:
Project-by-project isolation.
No conflicts between library versions.
Easier to share and reproduce a project (
requirements.txtorenvironment.yml).You can delete a project without polluting the system.
Two Main Choices: venv vs conda#
venv (native Python virtual environments)
Included in Python (
python -m venv myenv).Lightweight, simple to use.
Package management via
pip install.Good for:
Lightweight projects (Flask, Django, scripts).
General development.
⚠️ Limitations:
pipinstalls only Python libraries.Some heavy libraries (numpy, scipy, torch, tensorflow…) may require compilation → possible errors.
conda (Anaconda/Miniconda environments)
Also creates isolated environments (
conda create -n myenv python=3.10).Can install not only Python libraries, but also system dependencies (BLAS, MKL, CUDA, etc.).
Precompiled package distribution → fast and reliable installation.
Good for:
Data science and machine learning (numpy, pandas, scikit-learn, PyTorch, TensorFlow).
Multi-language projects (Python + R + CUDA…).
⚠️ Limitations:
Heavier than
venv.Package management can be slightly slower at times.
Important
⇨ Another reason to focus on the Anaconda solution
Conda Virtual Environments#
Conda: Creating a New Environment#
# create a new Conda environment with a specific Python version (Replace `myenv`
# with the name of your environment and `3.11` with the desired Python version)
conda create --name myenv python=3.11
# Activate the environment before working in it:
conda activate myenv
# When you are done, deactivate the environment to return to the base environment:
conda deactivate
Conda: Listing and Removing Environments#
# list all available environments:
conda env list
# remove an environment completely:
conda remove --name myenv --all
Conda: Installing Packages in an Environment#
# install a package in the active environment:
conda install numpy
# install a specific version of a package:
conda install numpy=1.25
# install multiple packages at once:
conda install numpy pandas matplotlib
Conda: Updating and Removing Packages#
# update a package in the current environment:
conda update numpy
# remove a package from the environment:
conda remove numpy
Conda: Exporting and Reproducing Environments#
# to share or reproduce an environment, export it to a YAML file:
conda env export > environment.yml
# create an environment from a YAML file:
conda env create -f environment.yml
Conda Tips#
Always use separate environments for different projects to avoid conflicts.
Update Conda regularly with
conda update conda.Use the
conda-forgechannel if a package is not found in the default channels:
conda install -c conda-forge package_name
Summary Table of Common Conda Environment Commands#
Task |
Command |
|---|---|
Create environment |
|
Activate environment |
|
Deactivate environment |
|
List environments |
|
Remove environment |
|
Install package |
|
Install specific version |
|
Install multiple packages |
|
Update package |
|
Remove package |
|
Export environment |
|
Create from file |
|
1.5. Setting Up the Conda Virtual Environment for This Project#
This section is intended for macOS users.
To run this Jupyter Book, I make use of a conda virtual environment, whose recipe i contained in the file environment.yml that describes everything needed to create the conda environment named python-dsspikes-env:
!cat environment.yml
name: python-dsspikes-env
channels:
- conda-forge
- defaults
dependencies:
- python=3.11
- numpy=1.26
- matplotlib=3.8
- pandoc=3.8 # removed build hash
- seaborn=0.12
- jupyter-book=1.0.4
- jupyterlab=4.1
- ipykernel
- csvkit
- pip
- pip:
- pyabf==2.3.8
name: python-dsspikes-env tells conda what name you assign to the environment. WHen you run:
conda env create -f environment.yml
Conda reads that line and creates an environment with that name. So after creation, you’ll activate it with:
conda activate python-dsspikes-env
Each time you run it, conda will move one step “up”: If you’re inside python-dsspikes-env, it will go back to (base). If you’re already in (base), it will deactivate completely (no environment active). So the cycle is:
conda activate python-dsspikes-env
# ... work here ...
conda deactivate
The quickest way to check which conda environment is active is:
conda info --envs
or its shorthand:
conda env list
hence:
(python-dsspikes-env) data-science-spikes$ conda env list
# conda environments:
#
base /Users/campillo/miniforge3
myenv /Users/campillo/miniforge3/envs/myenv
python-dsspikes-env * /Users/campillo/miniforge3/envs/python-dsspikes-env
The
*shows which environment is currently active.In your shell prompt, the active environment name also appears in parentheses, e.g.
(python-dsspikes-env) data-science-spikes$(here(conda_virtual_env) directory_name.
To check the active conda environment inside a Jupyter notebook, you have a few options:
Check
sys.executable
import sys
sys.executable # This shows the path to the Python binary being used.
'/Users/campillo/miniforge3/envs/python-dsspikes-env/bin/python'
Check environment variables
import os
os.environ.get("CONDA_DEFAULT_ENV")
'python-dsspikes-env'
Print Python packages & versions To confirm everything is coming from the right env:
!which python
!python --version
!pip list | grep -E "pyabf|matplotlib|seaborn"
/Users/campillo/miniforge3/envs/python-dsspikes-env/bin/python
Python 3.11.13
matplotlib 3.8.4
matplotlib-inline 0.1.7
pyabf 2.3.8
seaborn 0.12.2
and !pip list for the complete list.
Setting Up the Conda Virtual Environment for This Project
This project uses Python packages such as numpy, matplotlib, seaborn, and pyabf.
To ensure reproducibility and avoid conflicts with other Python projects, we recommend using a dedicated Conda virtual environment.
1. Create the environment - Run the following command in your terminal:
conda env create -f environment.yml
This will create a new environment named jupyter-env (as specified in
environment.yml).
All required packages for this Jupyter Book project will be installed.
2. Activate the environment
conda activate jupyter-env
Your terminal prompt should now show
(jupyter-env), indicating the environment is active.
3. Make the environment available in Jupyter
python -m ipykernel install --user --name=jupyter-env --display-name "Python (jupyter-env)"
This allows notebooks to select the correct kernel.
4. Verify installation - You can test that everything is installed correctly:
python -c "import numpy, matplotlib, seaborn, pyabf; print('All imports OK!')"
If no errors appear, the environment is ready to use.
5. Launch Jupyter Lab or Notebook
# Launch Jupyter Lab
jupyter lab
# or launch classic Jupyter Notebook
jupyter notebook
In the notebook (top right), select Kernel
→ Python (jupyter-env).
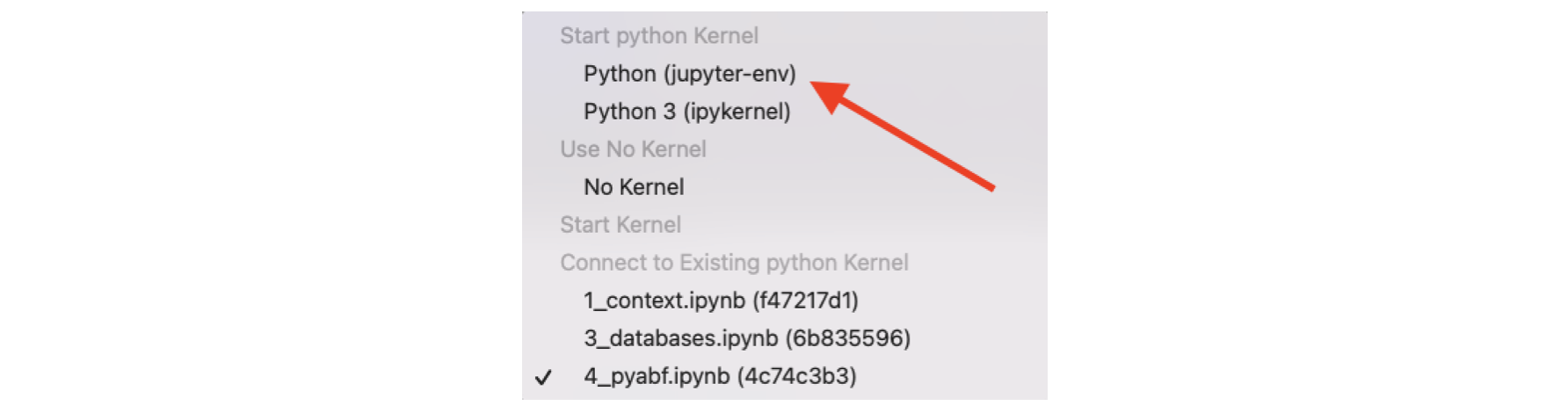
6. Updating the environment – If you modify environment.yml later (e.g., adding packages), update the environment:
conda env update -f environment.yml --prune
--pruneremoves packages no longer listed inenvironment.yml.
Notes:
Keep all project-specific packages inside the virtual environment; do not install them in base.
For reproducibility, commit
environment.ymlto your repository.